
Working on large language models for the past few years has taught me one crucial lesson: general-purpose models, no matter how capable, hit a wall when they encounter specialized domains like banking. At Kasisto, I’ve been driving development of KAI-GPT v4, and the journey has reinforced why domain expertise matters more than raw scale.
The Problem with “Just Use GPT-4”
When I talk to financial institutions about deploying AI, I hear the same question: “Why not just use GPT-4?” It’s a fair question. GPT-4 is impressive, and the temptation to plug it into banking systems is strong. But here’s what I’ve seen happen in practice: a chatbot hallucinates product details, a model misinterprets regulatory requirements, or worse, it confidently provides incorrect account information.
These aren’t just bugs – they’re compliance risks that can cost millions. Generic models trained on broad internet data fundamentally lack the specialized knowledge and safety guardrails that banking demands. You can’t prompt-engineer your way around this problem.
Our Approach: Quality Over Quantity
With KAI-GPT v4, we took a different path. We started with Google’s Gemma 3 12B parameter foundation model, which is significantly smaller than GPT-4, and fine-tuned it on 110 million tokens of carefully curated banking data. This wasn’t just scraping banking websites. Our dataset included:
- Open financial literature and regulatory documents
- 23,000 Q&A pairs from banking web crawls
- 18,000 synthesized conversations derived from real customer interactions
- Strategic inclusion of unanswerable questions (more on this below)
The key insight? Data quality matters far more than volume when building domain expertise.
Teaching a Model to Say “I Don’t Know”
Here’s something counterintuitive I learned: one of the hardest things to teach an LLM is when not to answer. Most models are rewarded for being helpful, which leads them to generate plausible-sounding answers even when they’re uncertain. In banking, this is catastrophic.
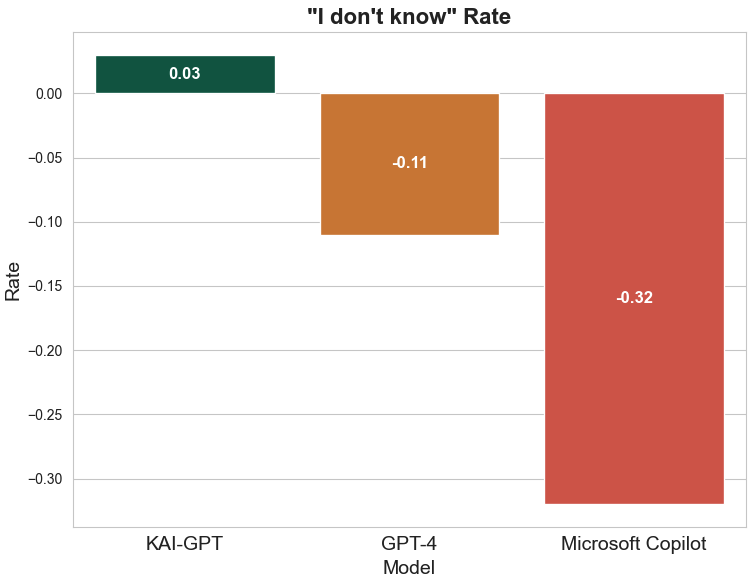
We tackled this by deliberately including unanswerable questions in our training data. The model learned to recognize the boundaries of its knowledge and respond with “I don’t know” rather than hallucinate. This might seem trivial, but it fundamentally changed how the model behaves in production.
We used an “LLM-as-a-Judge” approach to refine this behavior. Essentially, we had another model evaluate whether answers were appropriate or if the model should have declined to answer. This created a feedback loop that dramatically reduced hallucinations while maintaining helpfulness for questions the model should answer.
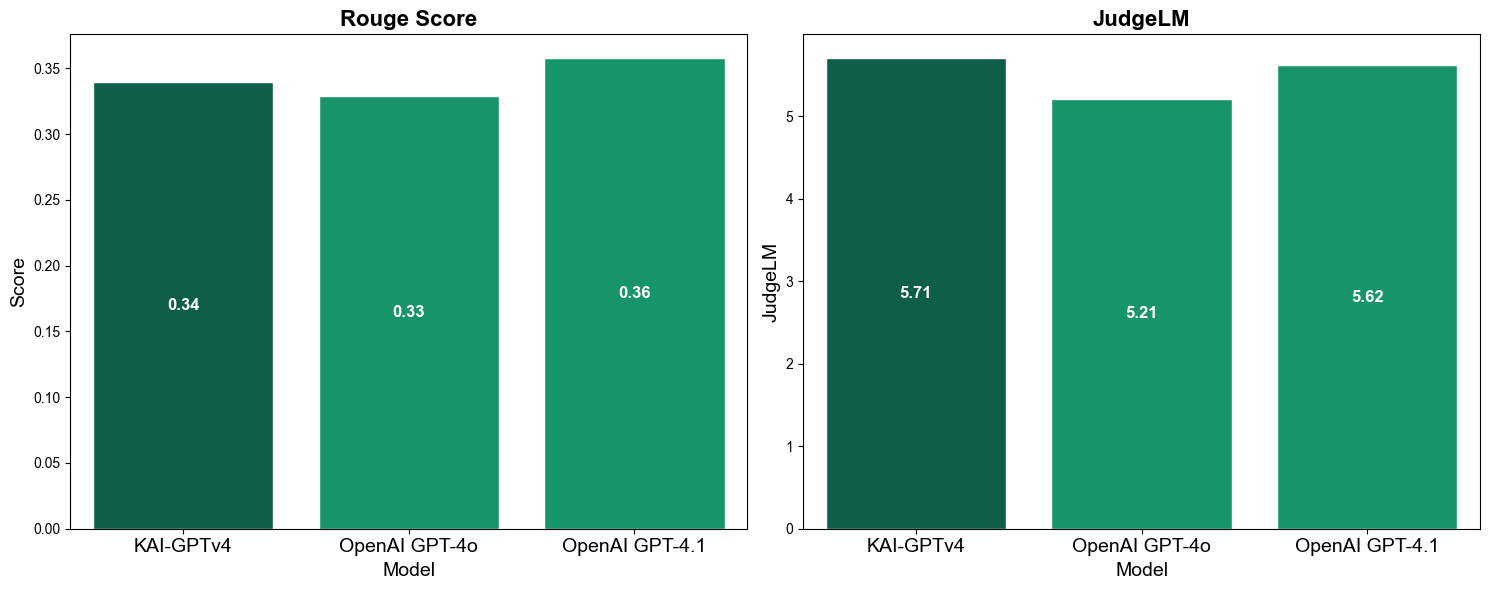
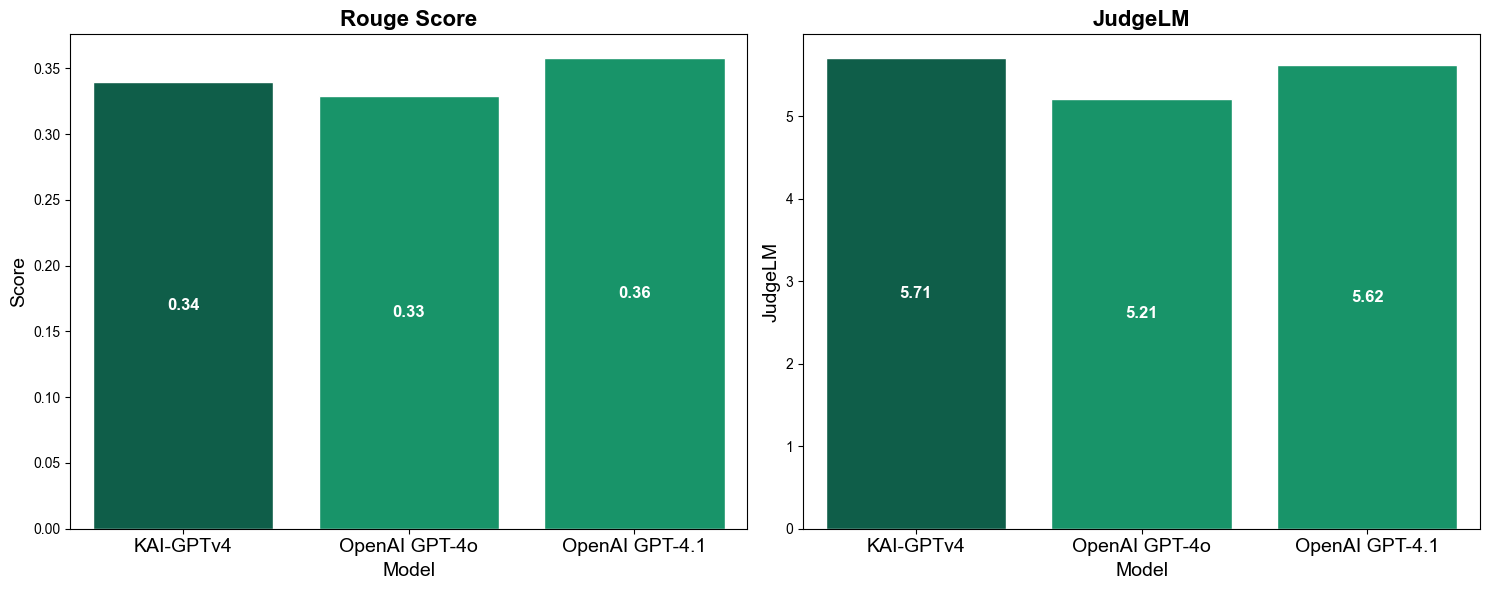
The results speak for themselves: our citation quality metrics score 10-15 points higher than GPT-4o and GPT-4.1 across every dimension we measured. When the model does answer, it backs up its claims with proper sources.
The Numbers That Actually Matter
When I show our benchmarks to technical audiences, I focus on metrics that translate to real business value:
- F1 score of 0.943 in question-answering tasks – this means the model correctly identifies and answers relevant questions with high precision
- 90.38% true positive rate – when there’s a valid answer, we find it 9 times out of 10
- 3x faster completion time than GPT-4 on a single RTX 6000 Ada GPU
That last metric deserves emphasis. We’re not just faster – we’re dramatically faster while running on commodity hardware. For financial institutions processing thousands of customer queries daily, this translates to lower infrastructure costs and better user experience.
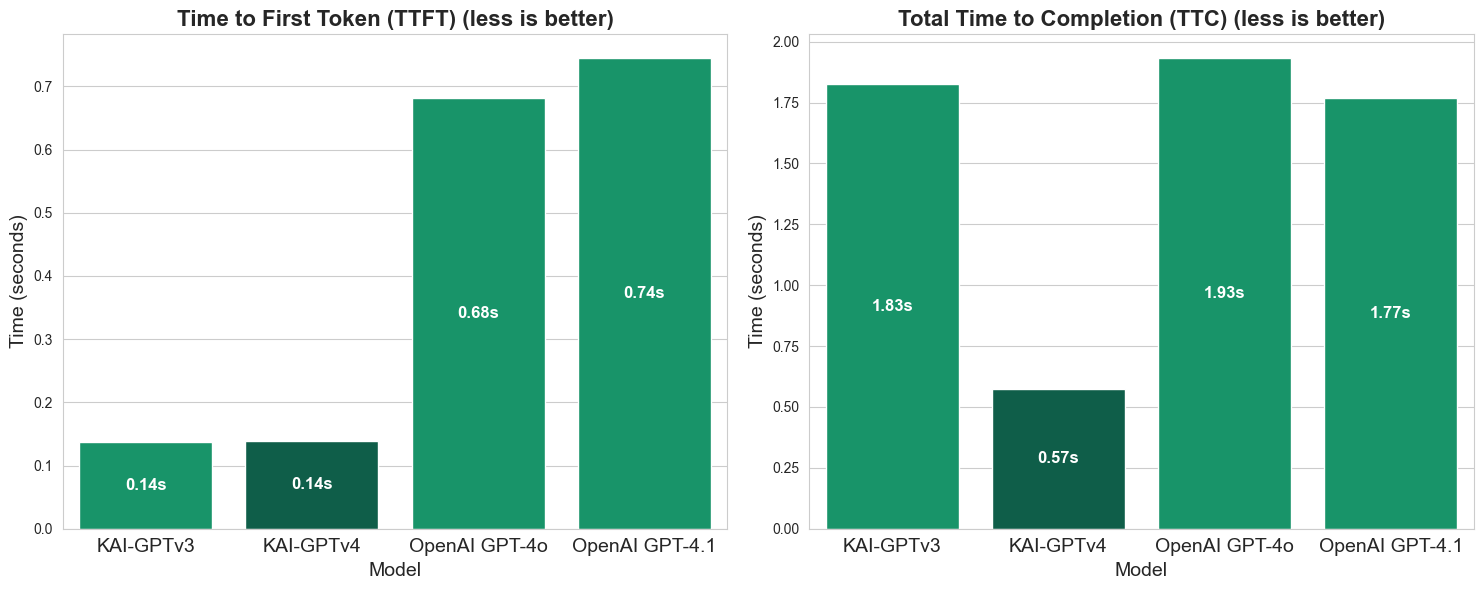
The speed advantage isn’t just about raw throughput. Faster inference means lower latency for end users. When a customer asks about their account balance, they get an answer in under a second instead of waiting several seconds. That difference matters in production.
What I Learned About Training Efficiency
One question I get frequently: “How long does it take to train a model like this?” The answer surprised even me. Using LoRA and DoRA fine-tuning techniques, we completed training in 360 hours on 8 RTX A6000 Ada GPUs.
That’s 15 days on relatively affordable hardware. For context, training GPT-4 reportedly took months on thousands of GPUs. Our approach proves you don’t need massive compute budgets to build production-grade domain models.
The 128,000 token context window has been particularly valuable in practice. Financial documents are long – loan agreements, regulatory filings, account histories. Being able to process these in their entirety without chunking or summarization preserves critical context that shorter windows would miss.
We also built in multimodal capabilities from the start. Banks don’t just deal with text, but also they handle scanned documents, statements with tables, and images of checks. Having native image understanding eliminates an entire preprocessing pipeline.
Why Specialization Beats Scale
Working on KAI-GPT v4 has reinforced something I’ve suspected for a while: for most real-world applications, domain specialization beats brute-force scaling. Yes, GPT-4 is more capable in general. But for banking specifically? Our focused 12B parameter model consistently outperforms models 10x its size.
The reason is simple: we’re not trying to do everything. We’re trying to do one thing exceptionally well. Every training decision, every data choice, every architectural tweak was optimized for banking tasks. That focus compounds.
For financial institutions dealing with GDPR, CCPA, and sector-specific regulations, this matters immensely. You can’t deploy a black-box model that might hallucinate compliance requirements. You need transparency, control, and the ability to explain model decisions. Smaller, specialized models give you that.
What’s Next
I’ve learned that in regulated industries like banking, being confidently wrong is far worse than admitting uncertainty. KAI-GPT v4’s willingness to say “I don’t know” isn’t a limitation, it’s a feature that makes the model trustworthy enough for production deployment.
As the field evolves, I expect we’ll see more specialization, not less. The trend toward ever-larger general models will continue, but the real value for most enterprises will come from domain-focused models that prioritize accuracy and reliability over general capability.
For me, this project reinforced that data quality, training methodology, and problem focus matter more than parameter count. Sometimes the best solution isn’t the biggest model – it’s the right model for the job.
Interested in learning more about KAI-GPT v4? Visit Kasisto’s blog for technical details and demo requests.