Building KAI-GPT v4: What I Learned About Domain-Specialized LLMs
Working on large language models for the past few years has taught me one crucial lesson: general-purpose models, no …
Read MoreRecent articles on AI, machine learning, and natural language processing

Working on large language models for the past few years has taught me one crucial lesson: general-purpose models, no …
Read More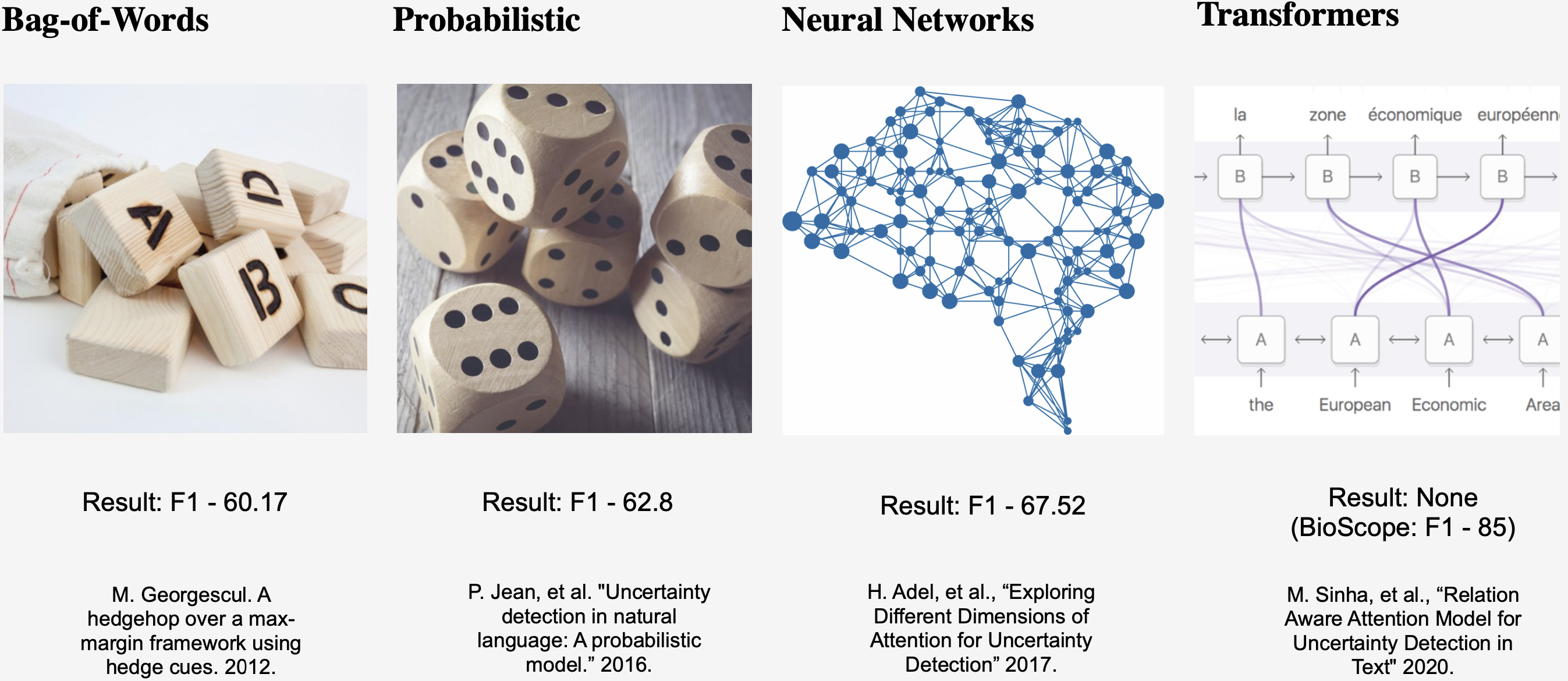
Imagine a doctor says “The patient likely has pneumonia” versus “The patient has pneumonia.” …
Read More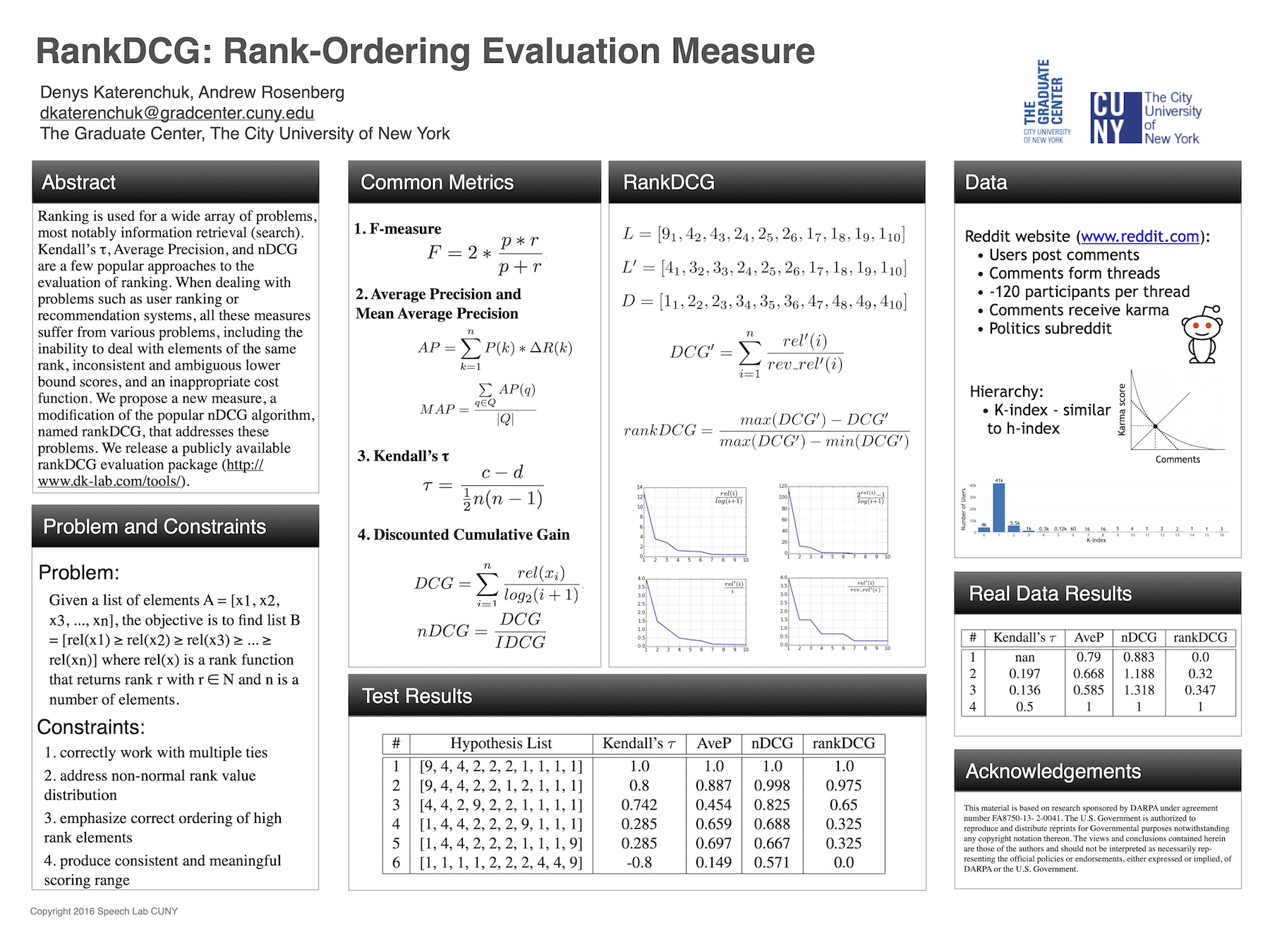
Advanced algorithms improve our lives in subtle, but consistent ways. Google search results seldom make us go to the …
Read More
For over ten years, my main work tool has been a laptop. For most tasks — whether it is software development or research …
Read More
Can public opinion predict stock market movements? With recent advancements in natural language processing …
Read More
This study presents a comprehensive text analysis of the pickup dating community through the lens of social …
Read More